Technical Brief
Cadence AI IP 平台
用于边缘到设备端 AI 的综合 IP 平台
随着不同应用和垂直行业愈发依赖 AI 来处理各种任务,设备端和边缘 AI 处理方案也越来越流行。这些解决方案被部署在具有不同计算性能和功耗要求的系统级芯片中,需要满足汽车、消费品、工业和移动应用等不同市场的需求,对IP 供应商和芯片公司来说都是一项挑战。Cadence AI IP平台上的各种产品组合可以帮助 SoC 开发人员根据项目要求,加速产品设计并交付解决方案。
Cadence IP 产品为 AI 处理提供了多项解决方案,基于通用的软件平台,针对不同的数据和设备端 AI 要求进行优化,以提供最佳的功耗、性能和面积 (PPA)。上述方案提供了可扩展、高能效的设备端及边缘 AI 处理能力,是人工智能 SoC 日益普及的关键。Cadence 的 AI IP 解决方案可以全面覆盖低端、中端和高端需求,是一套稳健的产品组合。
Overview
Neo NPU
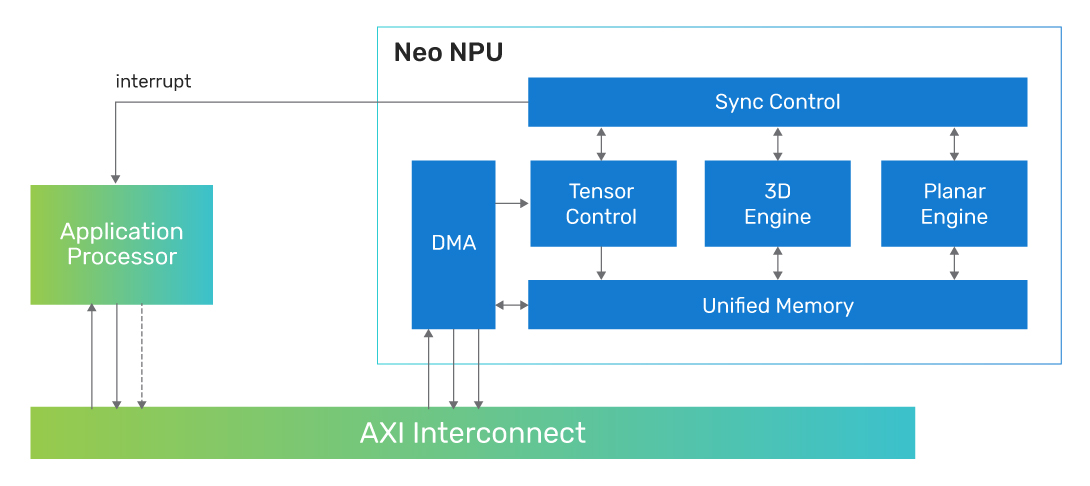
Cadence Neo NPU 是 Cadence AI IP 平台的旗舰产品,作为先进的神经处理引擎,它可以配合任意主处理器,提供高能效、高性能的 AI 处理能力。Neo NPU 广泛应用于各种领域,包括传感器、音频、语音、视觉、雷达等等。Neo NPU 可以提供灵活的算力水平,既适合物联网和耳机/可穿戴设备等超低功耗应用,也适合 AR/VR、汽车等高性能系统。
Neo NPU的产品架构可以满足不同网络结构和基本算子的需求,可以完全独立处理或近乎完全独立处理由主处理器分发的传统或生成式 AI 运算任务。根据应用的具体需求,主处理器可以是应用处理器、通用 MCU或者用于执行预处理/后处理和相关信号处理的DSP,无论主处理器如何选择,推理任务都由 Neo NPU来完成。
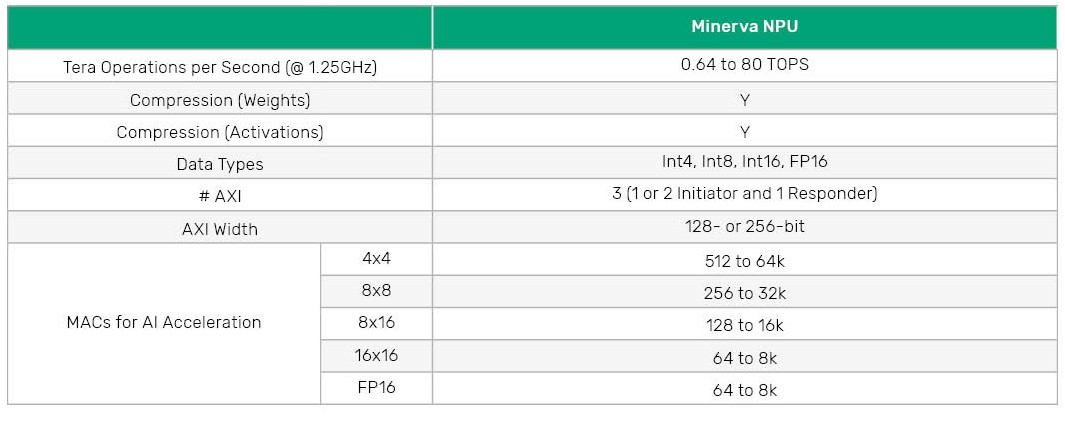
Neo NPU 的单核算力范围从单周期 256 MAC 至 32k MAC,用来满足不同的运算需求。算力水平按2的整数次幂顺序增长,可以为目标应用匹配合适的芯片面积。Neo NPU原生支持 Int4、Int8、Int16 和 FP16 数据类型,用于CNN、RNN 和Transformer等网络中的基本算子实现,配套的软件工具支持混合精度计算,从而在性能和精确度之间取得最佳平衡。
Neo NPU 的其他功能还包括数据压缩/解压缩,可以最大限度地降低网络占用的系统内存空间和带宽消耗。运算部件也会利用网络稀疏性来实现最佳性能和能效。
在 7nm 工艺下,Neo NPU 的典型时钟频率高达 1.25GHz,对应的单核性能可达 80 TOPS,客户还可以根据特定产品需求降低时钟频率。Neo NPU 组成多核系统后,性能提升至 80 TOPS 以上,可以满足高级生成式 AI、大型语言模型和基于 Transformer 的先进机器学习模型的需求。
Tensilica AI Base
Tensilica DSP在传统信号处理任务之外,也可以高效地执行 AI 运算任务。Tensilica DSP 包括用于音频/语音处理的HiFi DSP、用于图像处理的Vision DSP 以及用于雷达和通信处理的 ConnX DSP,各款DSP处理器搭配AI扩展指令,可以提供 8 GOPS至 2 TOPS不等的 AI处理性能。
这些DSP 基于 VLIW 和 SIMD 架构,设计有针对特定领域优化的指令集。基于成熟的 Tensilica DSP 架构,Tensilica AI 平台为客户提供了面向不同领域,高度可定制和扩展的解决方案。系统芯片设计师可以在基本架构上扩展面向不同任务的新指令,从而创造差异化的产品。
这些 DSP 处理器都有可扩展的乘累加器 (MAC) 模块,可以高效地执行自定义 AI指令 ,Cadence也在DSP上提供优化的NN 算子库和全面的软件支持。


Tensilica AI Boost
Cadence Tensilica NNE 110 是一款小型AI加速引擎,在Tensilica DSP指令的基础上,增加了32、64 或 128路 MAC,从而将 AI 处理能力扩展至最高 256 GOPS。NNE 110 与 Tensilica HiFi DSP 搭配使用,常用于低功耗芯片设计中,相比单独的HiFi DSP, NNE 110 + HiFi DSP的设计方案带来了4倍以上的 TOPS/W 性能,而每次推理消耗的能量却降低了80%


AI 软件支持
NeuroWeave 软件开发工具包 (SDK)可以支持所有 Cadence AI IP平台下的产品。
NN 编译器:自动化的端到端工具链
-
 修剪后的量化模型利用了稀疏的 AI 引擎
修剪后的量化模型利用了稀疏的 AI 引擎 - 修剪和聚类最多可将模型大小减少约 8 倍
- 张量压缩可降低内存带宽
- 解释器可为用户带来灵活性
- 用于实时执行的Delegates/ANN

NeuroWeave SDK 将神经网络模型转换为可以在嵌入式设备上运行的经过优化的可执行文件。NeuroWeave 是一个支持多种流程和运行环境的通用软件工具:
- 包括提前编译器工具链
- 可以执行轻微的修剪和压缩,以减少计算、内存流量和存储需求
- 用作命令行工具和 GUI,可以在客户的软件流程中轻松调用
- 可编程、可扩展,以适配不同的目标IP
- 足够的灵活性,以适应随时间快速变化的计算需求
- 支持混合精度计算(4 bit/8 bit/16 bit整数和 16bit半精度浮点数)
- 支持同时运行多个任务
Android NNAPI
Android Neural Networks API (NNAPI) 是一款安卓 C 语言 API,用于在安卓平台上运行机器学习类的计算密集型操作。Android Neural Networks (ANN) 框架可以为AI处理任务动态生成优化代码,所有 Vision DSP 均支持 ANN 框架。
TFLM
对 Tensor Flow Lite for Microntrollers 的支持包括 TFL 模型生成、TFLM 参考库和解释器等编译过程中需要的工具,以及 TFLM 应用和解释器的运行时环境。
- 包括在 Tensilica AI产品上深度优化的TFLM基本算子库
- TFLM 团队进行每日进行回归测试,确保 TFLM 可以在 Tensilica IP 上平稳运行
库支持
基于Tensilica AI 产品提供深度优化的神经网络算子库。该算子库为目标硬件提供最常见的层和核心算子的优化实现。程序员可以利用这些库函数在短时间内开发出高效的神经网络。Tensilica 会不断开发新的算子,并对算子库进行全面测试,确保为 AI 开发者提供更强大的性能和稳定性。
Tensilica DSP 通用工具链
我们的处理器随附一整套软件工具:
- 具有自动并发指令和矢量化功能的高性能 C/C++ 编译器,支持 VLIW 和 SIMD 功能
- 链接器、汇编器、调试器、分析器和图形可视化工具
- 一个全面的指令集模拟器 (ISS),用于快速模拟和评估性能
- 在处理大型系统或冗长的测试向量时,快速功能TurboXim 仿真器可提供比 ISS 快 40 倍至 80 倍的速度,进而实现高效的软件开发和功能验证
- 利用基于C 语言建模的 Tensilica Xtensa Modeling Protocol (XTMP) 模型和基于SystemC® 建模的 Xtensa SystemC (XTSC)模型, 可以进行系统仿真,利用XTSC 模型还可以实现SystemC 和RTL的管脚级混合协同仿真,实现快速且周期精确的系统仿真。
- 支持所有主流的后端 EDA 流程