Overview
Scalable and Power-Efficient Neural Processing Units
The Cadence Neo NPUs offer energy-efficient hardware-based AI engines that can be paired with any host processor for offloading artificial intelligence and machine learning (AI/ML) processing. The Neo NPUs target a wide variety of applications, including sensor, audio, voice/speech, vision, radar, and more. The comprehensive performance range makes the Neo NPUs well-suited for ultra-power-sensitive applications such as IoT, hearables/wearables, high-performance systems in AR/VR, automotive, and more.
The product architecture natively supports the processing required for many network topologies and operators, allowing for a complete or near-complete offload from the host processor. Depending on the application’s needs, the host processor can be an application processor, a general-purpose MCU, or a DSP for pre-/post-processing and associated signal processing, with the inferencing managed by the NPU.

Key Benefits
Differentiate Your Design, While Delivering Market-Leading Capabilities
Flexible System Integration
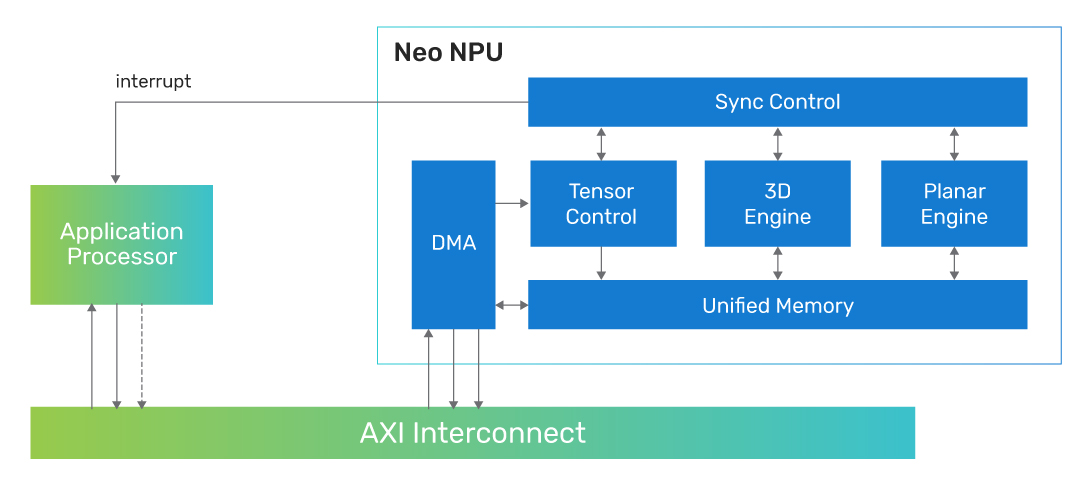
The Neo NPUs can be integrated with any host processor to offload the AI portions of the application
Scalable Design and Configurability
The Neo NPUs support up to 80 TOPS with a single-core and are architected to enable multi-core solutions of 100s of TOPS
Efficient in Mapping State-of-the-Art AI/ML Workloads
Best-in-class performance for inferences per second with low latency and high throughput, optimized for achieving high performance within a low-energy profile for classic and generative AI
Industry-Leading Performance and Power Efficiency
High Inferences per second per area (IPS/mm2 and per power (IPS/W)
End-to-End Software Toolchain for All Markets and a Large Number of Frameworks
NeuroWeave SDK provides a common tool for compiling networks across IP, with flexibility for performance, accuracy, and run-time environments
Features
Performance Options to Fit Your Application
Training & Support
Need Help?
Cadence is committed to keeping design teams highly productive with a range of support offerings and processes designed to keep users focused on reducing time to market and achieving silicon success.
Free Software Evaluation
Try our SDK Software Development Toolkit for 15 days absolutely free. We want to show you how easy it is to use our Eclipse-based IDE.
Apply NowTraining
The Training Learning Maps link opens in new tab help you get a comprehensive visual overview of learning opportunities.
Training News - Subscribe link opens in new tab
Online Support
The Cadence Online Support (COS) system fields our entire library of accessible materials for self-study and step-by-step instruction.
Request SupportXtensa Processor Generator (XPG)
The Xtensa Processor Generator (XPG) is the heart of our technology - the patented cloud-based system that creates your correct-by-construction processor and all associated software, models, etc. (Login Required)
Launch XPGTechnical Forums
Find community on the technical forums to discuss and elaborate on your design ideas.
Find Answers