Technical Brief
Cadence AI IP Platform
Comprehensive IP platforms for edge to on-device AI
With the increasing demand for AI-based tasks in various applications and vertical segments, on-device and edge AI processing is becoming more prevalent. As these solutions are deployed in SoCs with varying computational and power requirements, meeting the market needs for a wide range of automotive, consumer, industrial, and mobile applications can be challenging for both silicon IP providers and SoC companies. The comprehensive Cadence AI IP portfolio enables SoC developers to design and deliver their solutions in applications based on their KPIs and requirements.
Cadence IP products provide many solutions for AI processing, optimized for varying data and on-device AI requirements to provide optimal power, performance, and area (PPA) coupled with a common software platform. These deliver the scalable and energy-efficient on-device to edge AI processing that is key to today’s increasingly ubiquitous AI SoCs. Cadence’s comprehensive AI IP solutions span the low-, mid-, and high-end classes with a robust portfolio.
Overview
Neo NPU
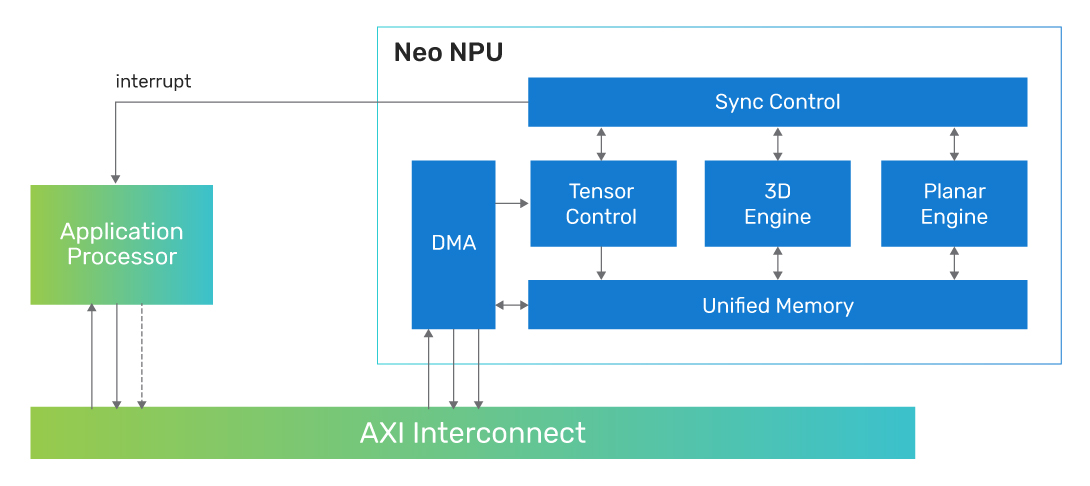
The Cadence AI IP platform is led by the Cadence Neo NPUs, advanced neural processing units that offer energy-efficient and high-performance AI processing that can be paired with any host processor. The Neo NPUs target a wide variety of applications, including sensor, audio, voice/speech, vision, radar, and more. The comprehensive performance range makes the Neo NPUs well suited across ultra-power-sensitive applications such as IOT and hearables/wearables, up to high-performance systems in AR/VR, automotive, and more.
The product architecture natively supports the processing required for many network topologies and operators, allowing for a complete or near-complete offload from the host processor for both classic and generative AI networks. Depending on the application’s needs, the host processor can be an application processor, a general-purpose MCU, or DSP for pre-/post-processing and associated signal processing, with the inferencing managed by the Neo NPU.
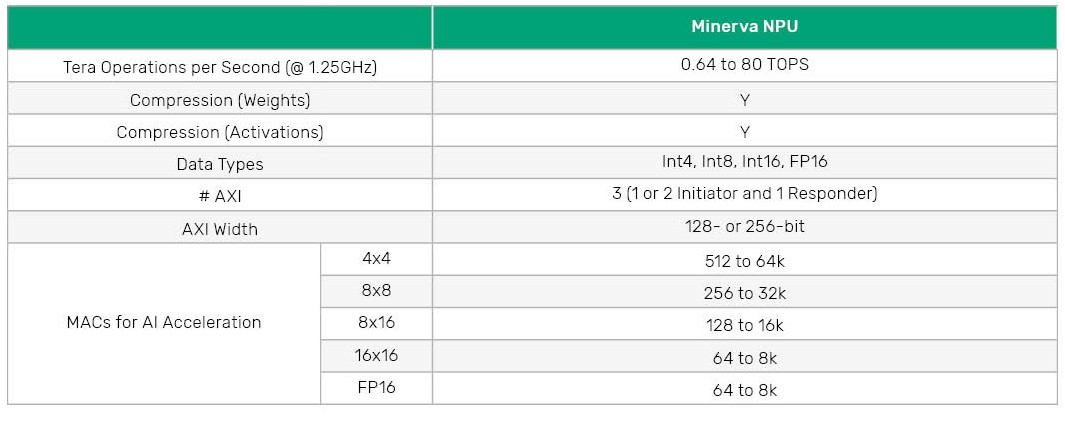
The Neo NPUs provide performance scalability from 256 up to 32k 8x8-bit MAC per cycle with a single core suiting an extensive range of processing needs. Capacity configurations are available in power-2 increments, allowing for the right sizing in an SoC for target applications. Int4, Int8, Int16, and FP16 are all natively supported data types across a wide set of operations that form the basis of CNN, RNN, and Transformer-based networks, with mixed precision supported by the hardware and associated software tools allowing for the best performance and accuracy tradeoffs.
Additional features of the Neo NPUs include compression/decompression to minimize system memory space and bandwidth consumption for a network and energy-optimized compute hardware that leverages network sparsity for optimal performance and power profile.
The Neo NPUs can run at typical clock frequencies of up to 1.25GHz in 7nm, yielding up to 80 TOPS performance in a single core, and customers can target lower clock frequencies for specific product needs. Neo NPUs can also be configured in a many-core or multi-core fashion to scale beyond 80 TOPS to address advanced Generative AI, Large Language Models, and Transformer-based state-of-the-art Machine Learning Models.
Tensilica AI Base
Tensilica DSPs are capable of efficient execution of AI workloads, in addition to traditional signal processing. The Tensilica DSP portfolio offers a wide range of performance, from 8 GOPS to up to 2 TOPS of AI performance, and includes the popular Tensilica HiFi DSPs for audio/voice, Vision DSPs, and ConnX DSPs for radar and communications, combined with AI ISA extensions.
The DSPs are based on the VLIW and SIMD architectures, with instruction sets optimized for specific domains. Tensilica AI platform customers benefit from the domain-specificity, extensibility, and configurability they have come to expect from the trusted, mature Tensilica DSP architecture. SoC designers can extend the base architecture to address specific workload requirements and create differentiation.
These DSPs also offer a scalable multiplier accumulator (MAC) block that can execute custom AI workloads efficiently, as well as an optimized NN library and comprehensive software support.


Tensilica AI Boost
The Cadence Tensilica NNE 110 engine is a compact engine capable of extending AI processing by adding a 32, 64, or 128 MAC offload for AI processing with up to 256 GOPS of performance. The NNE 110 is available in combination with Tensilica HiFi DSPs for power-sensitive designs. Consuming 80% less energy/inference on the AI engine, the NNE 110 allows the DSP to deliver more than 4X the TOPS/W.


AI Software Support
All Cadence AI IP products are supported through the unified NeuroWeave Software Development Kit (SDK).
NN compiler: Automated end-to-end toolchain
-
 Pruned quantized model exploits sparse AI engine
Pruned quantized model exploits sparse AI engine - Pruning and clustering reduce the model size by ~8X
- Tensor compression for lower memory bandwidth
- Interpreters for user flexibility
- Delegates/ANN for real-time execution

NeuroWeave SDK converts a neural network model into an optimized executable on the embedded target. NeuroWeave is a unified environment supporting multiple flows and run-time environments:
- Includes ahead-of-time compiler toolchain
- Can perform light pruning and compression to reduce computation, memory traffic, and storage needs
- Can be used as command line tools and as a GUI that can be easily invoked in a customer’s software pipeline flow
- Programmable and extensible framework adjusts to the target IP solution
- Is flexible and future-proof, as compute layers change rapidly over time
- Supports mixed-precision data formats (4-bit/8-bit/16-bit integer and 16-bit floating point)
- Provides concurrency support by running more than one workload at the same time
Android NNAPI
Android Neural Networks API (NNAPI) is an Android C API designed for running computationally intensive operations for machine learning on the Android platform. Android Neural Network (ANN) provides dynamic, optimized code generation for workloads. All Vision DSPs can support the ANN framework.
TFLM
Support for Tensor Flow Lite for Microcontrollers includes TFL model generation, compile time tools for the TFLM reference library and interpreter and runtime support for TFLM applications and interpreter.
- Includes NN libraries, which provide highly optimized implementations of TFLM operators on Tensilica products
- Daily regression testing by the TFLm team ensures TFLm works robustly on Tensilica IP
Library Support
Tensilica products offer a highly optimized neural network library. This library provides optimized implementations of the most common layers and kernels for the target hardware. A programmer can leverage these functions to develop highly efficient neural networks in a short time. Tensilica continually adds and develops new operators and thoroughly tests this library to ensure state-of-the-art performance and robustness for AI development.
Tensilica DSP Common Toolchain
Our processors are delivered with a complete set of software tools:
- A high-performance C/C++ compiler with automatic bundling and vectorization support for the VLIW and SIMD capabilities
- Linker, assembler, debugger, profiler, and graphical visualization tools
- A comprehensive instruction set simulator (ISS) allows you to quickly simulate and evaluate performance
- When working with large systems or lengthy test vectors, the fast, functional TurboXim simulator achieves speeds that are 40X to 80X faster than the ISS for efficient software development and functional verification
- Tensilica Xtensa Modeling Protocol (XTMP) for system modeling in C and Xtensa SystemC (XTSC) for system modeling in SystemC® provide for full-chip simulations, and the pin-level XTSC model offers co-simulation of the SystemC model at the pin level for fast, cycle-accurate system simulations
- All major back-end EDA flows are supported