- Overview
- Key Features and Benefits
- New Slack-Driven Placement Technique
- Advanced Timing- and PowerDriven Optimization
- Clock Concurrent Optimization with True Multithreading
- Routing and Interconnect Optimization Engine
- Accelerating TAT
- Advanced-Node Implementation Features
- Common UI for Ease of Use
- Cadence Services and Support
Datasheet
Innovus Implementation System
Meet PPA and TAT targets at advanced nodes
At advanced nodes, there’s a deep conflict between power, performance, and area (PPA) and design turnaround time (TAT). New physical and electrical design challenges emerge, and structures such as FinFETs create new considerations. To remain competitive, you can’t afford to make any tradeoffs to either PPA or TAT. With the features and functions available in the Cadence Innovus Implementation System, you won’t have to.
Overview
Overview
A physical implementation tool for high-density designs at advanced and established process nodes, the Innovus Implementation System delivers a typical 10%-20% PPA advantage along with an up to 10X TAT gain. Providing the industry’s first massively parallel solution, the Innovus Implementation System can effectively handle blocks as large as 5-10 million instances or more.
The Innovus Implementation System provides new capabilities in placement, optimization, routing, and clocking. Its unique architecture accounts for upstream and downstream steps and effects in the design flow to minimize design iterations and provide a runtime boost. Using the Innovus Implementation System, you’ll be equipped to build integrated, differentiated systems with less risk.
Key Features and Benefits
-
 Massively parallel architectures for handling large designs and supporting multi-threading on multi-core workstations, as well as distributed processing over networks of computers
Massively parallel architectures for handling large designs and supporting multi-threading on multi-core workstations, as well as distributed processing over networks of computers - New GigaPlace solver-based placement technology, which is slack-driven and topology-, pin access-, and color-aware to provide optimal pipeline placement, wire length, utilization, and PPA
- Advanced, multi-threaded, layer-aware optimization engine that is timing- and power-driven to reduce dynamic and leakage power
- Unique concurrent clock and datapath optimization engine for better cross-corner variability and performance with reduced power
- Next-generation slack-driven routing with track-aware timing optimization, which addresses signal integrity early on and improves post-route correlation
- Full-flow multi-objective technology to support concurrent electrical and physical optimization
- A customizable flow via a common UI and user commands across synthesis, implementation, and signoff with robust reporting and visualization, which facilitates design efficiency and productivity
New Slack-Driven Placement Technique
The Innovus Implementation System features the new GigaPlace engine, which changes the way placement is done and enhances PPA. Placement has traditionally been “timing-aware” and “lightly” integrated with other engines in the implementation system, such as timing analysis and optimization. The GigaPlace engine, on the other hand, is slack driven and tightly integrated. With this approach, the engine helps place the cells in a timingdriven mode by building up the slack profile of the paths and performing the placement adjustments based on these timing slacks.
The GigaPlace engine models accurate electrical constraints and physical constraints, such as floorplan, route topology-based wire length, and congestion. It also integrates the mathematical model of Cadence’s timing- and power-driven optimization engine, another component of the Innovus Implementation System. This integration makes concurrent, convergent optimization of electrical and physical metrics possible. You are also equipped to extract your design intent automatically from the electrical constraints, so you can achieve better optimization for physical metrics.
The Innovus Implementation System features a global optimization strategy and a novel numerical solver to avoid the trap of local minima. This avoids costly design iterations between different steps of the flow and results in a faster design closure with the best PPA.
In addition to solving for overlap and wire length, the GigaPlace engine solves for slack that is driven by gate delay, false/ multi-cycle paths, layer assignment, and congestion timing effects. As a result, you get better total negative slack (TNS)/ worst negative slack (WNS), wire length, congestion, spreading, and power. In summary, the GigaPlace engine is:
- Electrically driven, accounting for multi-mode/multi-corner (MMMC) slack, skew, and power
- Physically driven, accounting for routing topology, layer, color, and pin access
- Optimization driven, accounting for gate sizing and buffering
Pin access has become a new design closure metric. The GigaPlace engine, as shown in Figure 1, accounts for pin density, providing an adaptive pin access flow that automatically spaces cells based on the neighboring instance’s pin-access restrictions, and not just high local pin density. A proprietary algorithm in the tool globally plans how the router will access each pin (this is based on instances, not library cells). The GigaPlace engine has a cell spreading cost function that considers more design rule check (DRC) rules and pre-routes. An optimization cost function considers both horizontal and vertical cell spreading, and there’s an in-row space juggling function during legalization.
The GigaPlace engine, with its automatic density screen technology, simplifies the process of resolving congestion by automatically adding density screens in floorplan-induced high traffic areas. The algorithm analyzes floorplans, traffic patterns, and congestion maps to keep standard cells away from the congested area, such as narrow channels, notches, and macro boundaries. This helps reduce congestion without requiring you to add these density screens yourself.
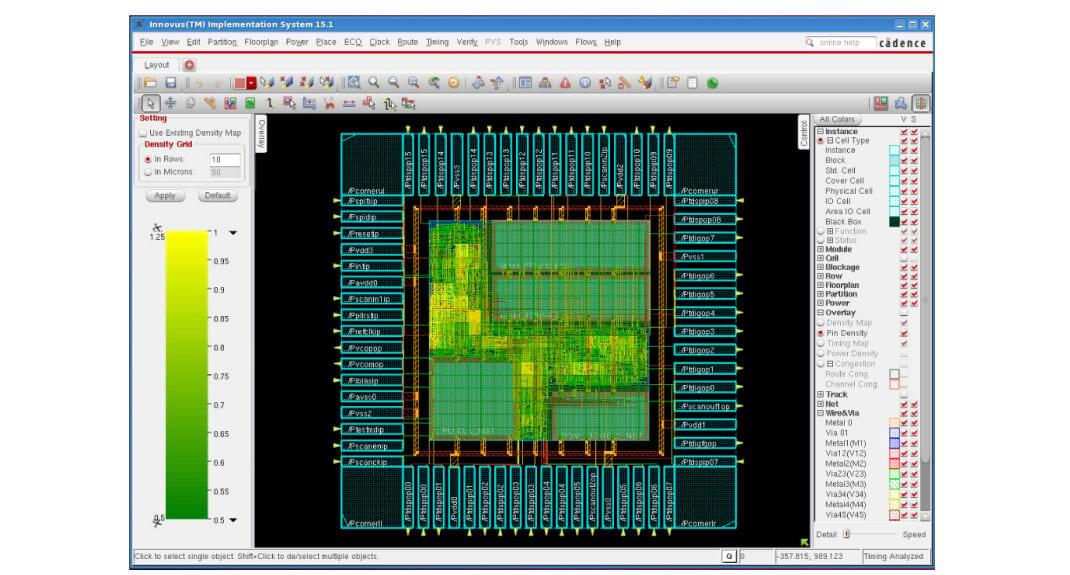
Figure 1: The GigaPlace engine accounts for pin density as well as pin access.
Advanced Timing- and PowerDriven Optimization
Through its route-aware optimization capability, the next-generation, multithreaded advanced timing- and powerdriven optimization engine in the Innovus Implementation System can:
- Identify long timing-critical nets
- Query a new congestion-tracking infrastructure to ensure that there’s space available on the upper layers
- Rebuffer these nets on the upper layers in order to improve timing
With these capabilities, you can maintain critical layer assignments during the entire pre-route optimization flow. These assignments are passed on to the system’s next-generation massively parallel global routing engine so that the final routing will also have the correct layer assignment.
The optimization engine also helps reduce dynamic and leakage power while facilitating optimal performance. A decision engine inside the system makes use of a rich library of power-aware transforms to step through the available options and reclaim power without affecting timing. This minimizes leakage, as well as internal and switching power globally.
The engine supports multiple formats: VCD, TCF, SAF, and SAIF. If switching activity data is unavailable, the engine employs probability-based propagation. The engine thus makes the best judgment in terms of finding the optimal power solution to lower power of an SoC without compromising on performance or area.
Clock Concurrent Optimization with True Multithreading
The Innovus Implementation System features a next-generation clock concurrent optimization engine with true multithreading, enhanced useful skew, and flow integration. The engine merges physical optimization with clock-tree synthesis (CTS), simultaneously building clocks and optimizing logic delays based directly on a propagated clocks model. All the optimization decisions are based on true propagated clocks and account for clock gates, inter-clock paths, and on-chip variation (OCV) derates.
A new FlexH feature in the implementation system provides a structure that is topologically as close to an H-tree as possible, with tradeoffs between different soft and hard constraints. This feature democratizes the H-tree approach to a real-world SoC design environment. Without this capability, designers would typically use mesh or a hand-created tree—architecturally limited and powerhungry approaches. The FlexH feature employs an advanced heuristic search algorithm, which explores millions of different possible tree structures to find the best compromise between avoiding blockages and power rails. The algorithm adheres to partition, module, and powerdomain constraints and optimizes insertion delay, power, and skew.
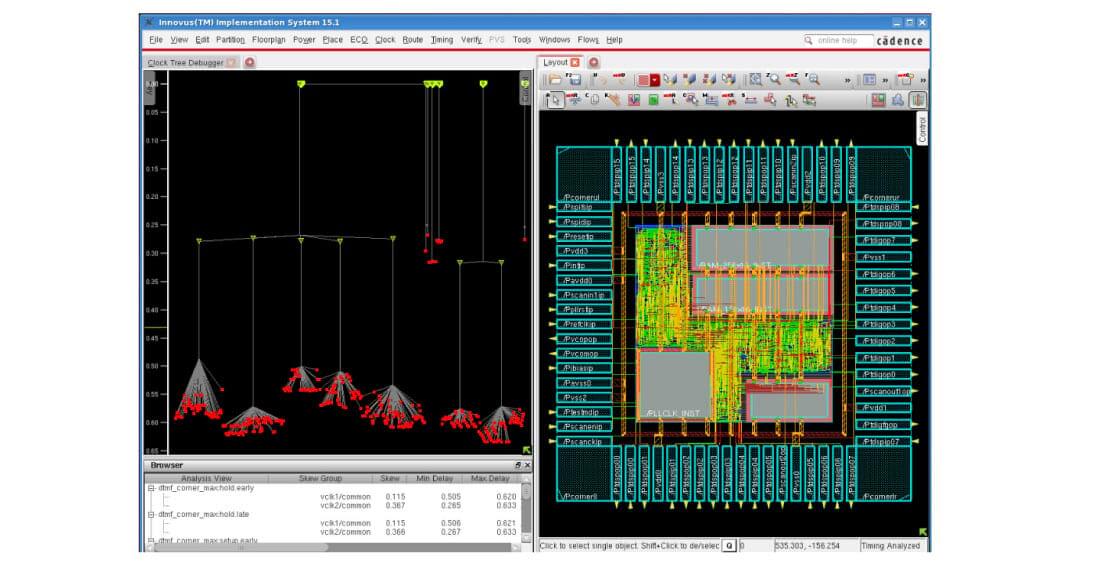
Figure 2: Concurrent clock and datapath optimization, along with a clock-tree debugger.
Routing and Interconnect Optimization Engine
The Innovus Implementation System features a proven routing and interconnect optimization engine that facilitates total routing convergence on timing, area, power, signal integrity, and manufacturing goals. This engine, with its massively parallel architecture, provides full-flow timing correlation, deterministic multithreading, and a flexible 2D/3D congestion mode.
The Early Global Route (eGR) feature brings further improvements in TNS and WNS, along with predictable design closure. The routing and interconnect optimization engine also:
- Fixes signal integrity issues before detail route
- Reduces timing jump between pre-route and post-route
- Allows change in netlist and cell locations
The NanoRoute tool also provides a structured router capability that can be used for selective pre-routes, shielding, and high-frequency bus routing, as well as for nets having length/resistance matching requirements.
Accelerating TAT
The Innovus Implementation System accelerates digital design TAT through various features, including its full-flow massively parallel architecture. The architecture, which supports multi-threaded tasks simultaneously on multiple CPUs, is designed such that the system can produce best-in-class TAT with standard hardware, which is normally 8-16 CPUs per box. In addition, for designs with a larger instance count, the flow can scale over a larger number of CPUs. The system’s advanced timing- and power- driven optimization engine provides threaded MMMC timing. As the number of MMMC views increases, the engine delivers a sub-linear speedup.
The system’s routing engine is designed such that routing and post-route closure are handled on additional CPUs—more than 100 if needed for larger designs. Backed by its processing speed, the routing engine simultaneously evaluates and optimizes interconnect topology based on the effects on timing, area, power, manufacturability, and yield. With its correct-by-construction approach, the engine can resolve potential doublepatterning conflicts on the fly to create a routing topology that is correct for double patterning and DRC the first time and also more area efficient. The engine is equipped with a deterministic multithreaded backplane, provides full-flow timing correlations, and offers a flexible 2D/3D congestion mode. It also features a track-based optimization algorithm, which fixes signal integrity issues before detail routing, reduces the timing jump between pre-route and post-route, and enables faster design closure.
Advanced-Node Implementation Features
The Innovus Implementation System has a complete feature set to address the requirements needed for implementation at advanced FinFET nodes. Special features are available to handle the placement needs for macros and standard cells early in the floorplanning stage. The placement engine has updates to handle pin access requirements for advanced-node libraries and the NanoRoute tool can handle and optimize routes for self-aligned double patterning technology. The new Via Pillar insertion flow and methodology allow you to push performance while meeting electromigration requirements. The updated optimization engine can accurately model the low voltage effects to give near signoff quality static timing results for faster design convergence.
Common UI for Ease of Use
The Innovus Implementation System is integrated with Cadence’s Tempus static timing analysis, Quantus extraction, and Voltus power integrity technologies, so you can accurately model the timing, parasitics, and signal and power integrity issues at the early stage of physical implementation. This facilitates faster convergence on these electrical metrics, resulting in faster design closure.
The implementation system has a common UI with Cadence’s Genus Synthesis Solution and the Tempus Timing Signoff Solution. The system simplifies command naming and aligns common implementation methods across these Cadence digital and signoff tools. For example, the processes of design initialization, database access, command consistency, and metric collection have all been streamlined and simplified. In addition, updated and shared methods have been added to run, define, and deploy reference flows. These updated interfaces and reference flows increase productivity by delivering a familiar interface across core implementation and signoff products. You can take advantage of consistently robust RTL-to-signoff reporting and management, as well as a customizable environment.
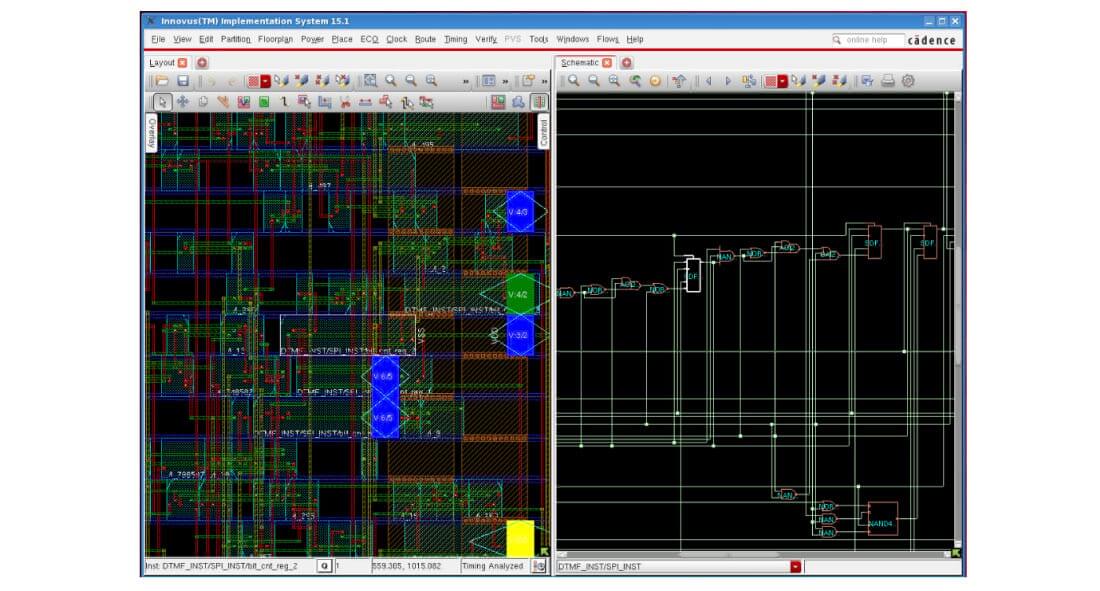
Figure 3: Cross-probing design layout with schematic viewer